Islandora CLAW MVP
Motivation
The Islandora CLAW project is currently transitioning from a prototype into a competitive product, and has had a requirements change from integration with Drupal 7 to Drupal 8. In order to aid in that transition, we are defining the minimum viable product. This will defend against scope creep, give clearly defined goals for community members to work towards, and present the point at which the CLAW team feels the software is ready to be tested out in small installations.
Needless to say, since this is a minimum product, a lot of parts of the previous prototype are either going to get replaced by an existing project to ease the maintenance load, or be removed altogether until time and resources allow other development.
High Level Features
These are what are considered the minimum requirements for a functional Islandora CLAW that is worthy of a 1.0.0 release.
- Content modeled in Drupal as Entities using PCDM 1.0
- REST API exposed for Drupal Entities
- Support for collections, images, books, and pages
- The ability to control metadata mappings between Drupal and RDF
- Provide RDF based default descriptive metadata profile in Drupal
- The ability to export/import JSON-LD
- Automatic backup of Drupal content in Fedora 4
- Ability to restore/bootstrap a Drupal site from a properly structured Fedora 4 repository
- The ability to index and search resources with Apache Solr
- The ability to restrict access to collections and/or individual resources across all representations (Drupal, Fedora, Solr, etc…)
- Asynchronous derivative generation
- Vagrant environment for development purposes, which will serve as a starting point for more complicated, distributed installs
Architecture
Overview
Islandora is composed of four broad categories of technologies. On one end, there is the administrative interface, which users and other clients will interact with. On the other is a repository, which will hold binary data and RDF triples. In between the two are connectors, which are small pieces of software that react to events from either administrative interface or the repository. These connectors will utilize microservices -- small utilities exposed as web services either internally or out on the internet at large.

Administrative Interface
Drupal 8
Drupal 8 provides a content management system (CMS for short) that allows end users the ability to create, edit, publish, and present digital content. Clients will interact with Drupal 8 via a browser or through a http client (such as cURL) in order to manipulate digital content. With each write operation, messages will be emitted to an event stream for processing by connectors.
SQL DB
Drupal 8 requires a MySQL (or drop-in replacement) or Postgres database.
Search Engine
Existing Drupal 8 modules for Apache Solr or Elastic Search will be utilized to provide full text search.
Microservices
A microservice is a small web service with functionality related to a single problem, even if it exposes just a single function. It can be deployed and configured independently of any other service, even having its own database if necessary. It can even be something that we don’t directly maintain or control ourselves.
ID Mapping Service
Identifiers between Fedora and Drupal need to be aligned so we can trace our way from one end of the system to the other. Implementing it as a microservice decouples this functionality from the rest of the codebase, allowing it to change or be pluggable with different mapping functions. It will utilize its own database. The ID indexing connector will be its primary client, updating the registry of IDs in response to repository events.
Image Conversion Service
Image conversion is a common operation in a content repository. Thumbnails, lower resolution copies for everyday access, and JP2s for use with IIIF image servers need to be generated when preservation masters are added or updated. This can be easily implemented by exposing ImageMagick’s convert command as a microservice.
Text Extraction Service
Text extraction on PDFs or images of written text can be utilized to provide searching capabilities on content of a book or document. Ghostscript can be used on text based PDF’s. Images will require an OCR utility like Tesseract.
FITS Web Service
The FITS web service is an already existing project that extracts technical metadata and produces FITS xml files.
Repository
Fedora
Fedora 4 houses binary content along with RDF triples for metadata about repository content. It also conforms to the LDP specification, allowing for manipulation of relationships through HTTP operations.
API-X
API-X allows Islandora to extend the Fedora 4 API. Microservices are registered in API-X and then ‘bound’ to repository content. A proxy sitting in front of Fedora exposes microservices as functions on repository content, which all HTTP requests must be routed through.
For example, suppose Islandora is running the FITS web service described above. Then let’s say we ‘bind’ it to all binaries in Fedora, with an identifier of ‘fits’. If we have a binary file at http://fedora-host.com/fcrepo/rest/binaries/example, then instead of writing code to retreive the content and forward it to our FITS service, we simply visit the proxy at http://apix-host.com/fcrepo/rest/binaries/example/fits.
Since services can be described, and that information is made available to interested clients, other applications can make informed decisions about what services are available for particular resources.
Triplestore
RDF content is indexed in a SPARQL 1.1 compliant triplestore.
Connectors
Connectors are small programs that listen to the event streams of either the Fedora repository or Drupal. In response to events, they perform actions, often bridging two pieces of technology together (like indexing a triplestore, hence ‘connectors’). Apache Camel is a natural fit for these types of programs.
Connectors will often delegate larger chunks of work to microservices, either bound to content through API-X or used stand-alone. They are primarily concerned with guaranteeing that events are responded to in a idempotent fashion. Due to the nature of asynchronous messaging, certain guarantees, such as timeliness of delivery, cannot be made. So connectors may need to retry a couple of times, or know to ignore a message that’s delivered late or applied twice. This is why it’s important that operations are idempotent.
ID Indexer
A connector will listen to Fedora events and index unique IDs contained in RDF using the ID Mapping microservice. The predicate used to notate unique IDs can be controlled through configuration.
Triplestore Indexer
A connector will listen to Fedora events and index RDF in a SPARQL 1.1 triplestore. This is provided by the Fedora community as part of the fcrepo-camel-toolbox project.
Sync
A sub-project of Alpaca that provides two connectors for keeping information between Fedora and Drupal in sync. One, which indexes content in Fedora from Drupal events, is always running. The other, which indexes content in Drupal based on state in Fedora, is manually triggered through a re-indexing process like other fcrepo-camel-toolbox connectors.
Alpaca
Alpaca responds to creation and update events for binary files and creates derivative files based on the microservices it finds available for that type of binary in API-X. Derivatives are then ingested into Drupal, with Sync making sure they get flushed back to Fedora.
Request Flows
Here are the proposed flows for all the different types of requests you can make against repository objects.
Read a Resource
Suppose a client views a resource in Islandora through their browser. A request is made to Drupal, which looks up the resource in an SQL database, and its representation is returned to the user.

Create a Resource
Suppose a client submits a form to create a new Resource, or provides a json-ld or binary representation to an entity REST endpoint. The supplied representation is used to create an entity in Drupal. In response to the entity being saved, an event is emitted with supplied representation as the body. The response is then sent back to the client. If using a browser, the client should be redirected to the newly created resource.
Meanwhile, Sync will receive the creation event, and ingest the supplied representation in Fedora. Fedora will then emit a creation event.
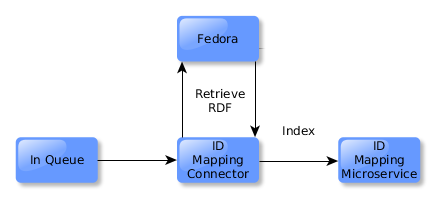
The ID Mapping connector will react, retrieving the Fedora representation and extracting an ID out of the RDF. That ID will be indexed in the ID Mapping microservice.
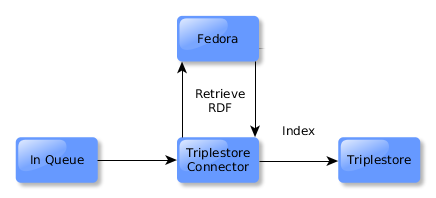
The triple store connector will also react, retrieving RDF and indexing it in the triple store.
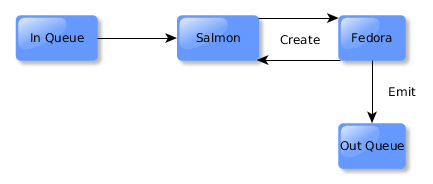
If the node created was a preservation master, then Alpaca will respond by inspecting the list of derivative generation services bound as extensions on the preservation master in API-X. Each will be invoked, with the new resource getting ingested into Drupal.
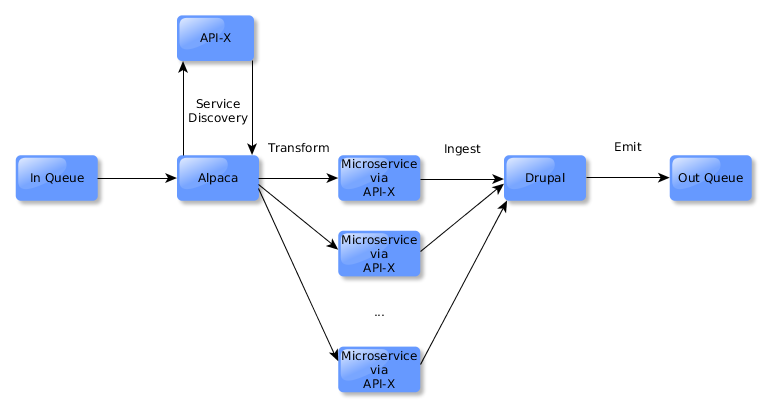
The process repeats itself again, with new events being emitted for the new entities getting created in Drupal. Sync responds and ingests the derivatives into Fedora.
Fedora emits the creation events, but since none are a preservation master, Alpaca does not respond and the cycle is broken.
Update a Resource
Suppose a client submits a form to update a new Resource, or provides a json-ld or binary representation to an entity REST endpoint. In response to the entity being saved, an event is emitted with supplied representation as the body. The response is then sent back to the client.
Meanwhile, Sync will receive the update event, and apply it against the representation in Fedora. Fedora will then emit an update event.
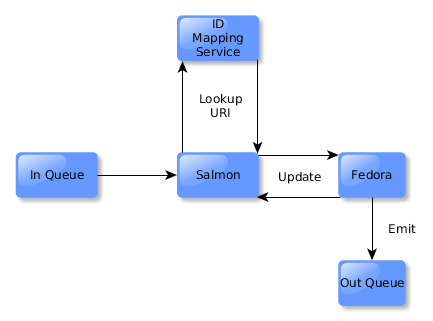
The triple store connector will also react, retrieving RDF and indexing it in the triple store.
If a binary of a presentation master was updated, then Alpaca will respond by inspecting the list of derivative generation services bound as extensions on the preservation master in API-X. Each will be invoked, with the new resource overwriting its predecessor in Drupal.
The process repeats itself again, with new events being emitted for the derivative entities getting updated in Drupal. Sync responds and ingests the derivatives into Fedora.
Fedora emits the creation events, but since none are a preservation master, Alpaca does not respond and the cycle is broken.
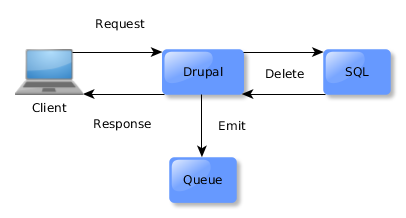
Delete a Resource
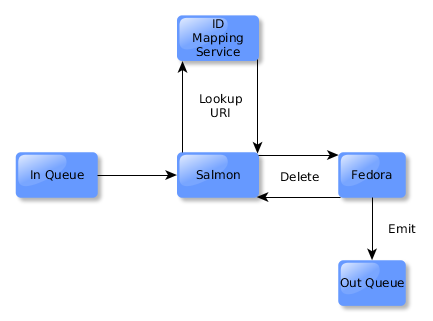
Suppose a client deletes a resource through the browser or API. In response to the entity being deleted, an event is emitted. The response is then sent back to the client.
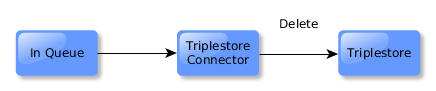
Meanwhile, Sync will receive the delete event, and remove the corresponding resource in Fedora.
The ID Mapping connector will respond to the delete event by removing the resource’s entry.
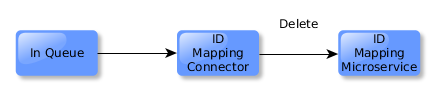
The triple store connector will also respond, deleting all triples with subject of the resource.
Content Modeling in Fedora
Descriptive metadata will be RDF properties, and a default dcterms descriptive metadata application profile will be created.
Technical metadata will be RDF properties, and follow the Hydra/Islandora led technical metadata application profile.
Here are Turtle snippets representing the default collection, object, and file types.
Collection
<> a pcdm:Collection .
dc:title “Collection Title” .
dc:description “Collection description” .
… other descriptive metadata …
Image
<> a pcdm:Object, schema:ImageObject .
pcdm:memberOf <someCollection>
dc:title “Image Title” .
dc:description “Image description” .
… other descriptive metadata …
Image Preservation Master File
<> a pcdmuse:PreservationMasterFile .
pcdm:fileOf <someImage>
ebucore:hasMimeType “image/jpeg”
… other technical metadata …
Image Service File
<> a pcdmuse:ServiceFile .
pcdm:fileOf <someImage>
ebucore:hasMimeType “image/jpeg”
… other technical metadata …
Image Thumbnail File
<> a pcdmuse:ThumbnailImage .
pcdm:fileOf <someImage>
ebucore:hasMimeType “image/png”
… other technical metadata …
Book
<> a pcdm:Object, schema:Book .
pcdm:memberOf <someCollection>
iana:first <firstPageProxy>
iana:last <lastPageProxy>
dc:title “Book Title” .
dc:description “Book description” .
… other descriptive metadata …
Page
<> a pcdm:Object, schema:ImageObject .
pcdm:memberOf <someBook>
dc:title “Page Title” .
dc:description “Page description” .
… other descriptive metadata …
Page Proxy
<> a ore:Proxy
ore:proxyFor <somePage>
ore:proxyIn <someBook>
iana:prev <prevPageProxy>
iana:next <nextPageProxy>
Page Preservation Master File
<> a pcdmuse:PreservationMasterFile .
pcdm:fileOf <somePage>
ebucore:hasMimeType “image/tiff”
… other technical metadata …
Page Intermediate File
<> a pcdmuse:IntermediateFile .
pcdm:fileOf <somePage>
ebucore:hasMimeType “image/jp2”
… other technical metadata …
Page Service File
<> a pcdmuse:ServiceFile .
pcdm:fileOf <somePage>
ebucore:hasMimeType “image/jpeg”
… other technical metadata …
Page Thumbnail File
<> a pcdmuse:ThumbnailImage .
pcdm:fileOf <somePage>
ebucore:hasMimeType “image/png”
… other technical metadata …
Drupal 8
Objects will be modeled using content entities in Drupal 8. The content entities store their metadata as Drupal fields, which are mapped to RDF using an rdf mapping. An RDF mapping not only allows metadata to be transformed into json-ld, but it also controls which properties from Drupal get preserved in Fedora.
Files will be modeled using media entities. Media entities attempt to provide the base storage component for the Drupal 8. They can model any type of media, including local files, YouTube videos, Tweets, Instagram photos, etc…
Ingests and edits can be done for an entire graph of entities using inline entity forms. Although flushing back to Fedora happens at the per-Resource level, using inline entity forms makes the named graph the default unit of work for a repository architect.
Here’s an example of what an ingest form could look like using inline entity forms:
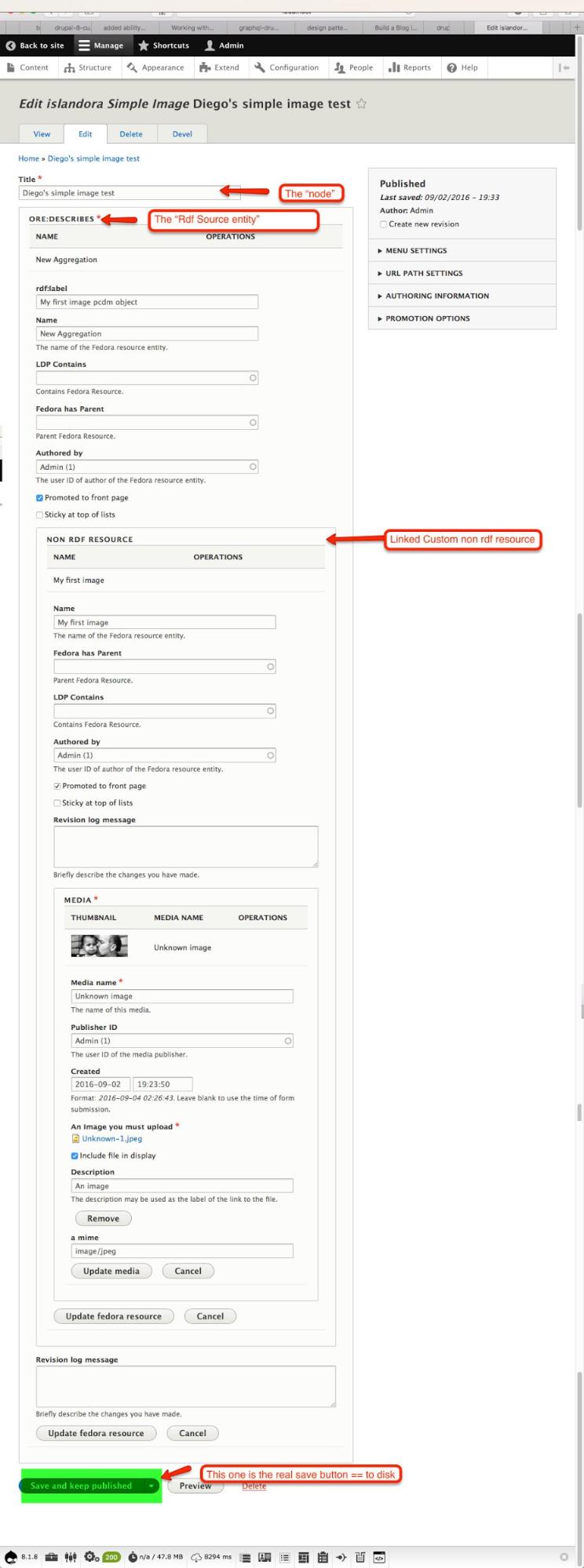
Here’s a list of the entities required to meet our goals. Each of these entities must have basic RESTful CRUD operations exposed for clients.
- RdfResource
- NonRdfResource
- Proxy
- Object
- File
- Collection
- Image
- Page
- Book
Individual entities and named graphs can be imported and exported in json-ld format using json-ld contexts.